Jakiś czas temu, podczas porządkowania szafy wpadły mi w ręce, moje stare szpargały. Notatki z wykładów z mechaniki kwantowej, które to notatki jako student w latach 90-tych skrzętnie prowadziłem. Gdy już się nacieszyłem wspomnieniami zacząłem się zastanawiać czy nie dałoby się nieco poprawić ich wyglądu, oczyścić ze zbędnych elementów. Na każdej stronie widnieje niebiesko-blada kratka, dodatkowo pojawiają się przebitki atramentu z drugiej strony kartki. Widoczne są również otwory na wpięcie do segregatora.

Ponieważ ręczne czyszczenie nie wchodziło w grę, wybór padł na algorytm K-Means – powszechnie stosowany w różnych obszarach Machine Learning / Artificial Intelligence. Pomyślałem sobie, że skoro radzi sobie dobrze jako pomoc w medycznym obrazowaniu to powinien poradzić sobie i z moimi notatkami.
Opis Problemu
K-Means bywa używany do automatycznej klasyfikacji zarówno punktów w przestrzeni rzeczywistej, jak i w przestrzeni kolorów RGB. W tym ostatnim przypadku, nierzadko jako algorytm redukujący liczbę kolorów. W naszym przypadku, zamiast redukcji kolorów, pozbędziemy się całkowicie klastrów z przestrzeni RGB do których należą punkty spoza samego tekstu – takich jak niebieska kratka, czy widoczne przebitki z drugiej strony. A ujmując rzecz ściślej – pozostawimy tylko jeden klaster – ten który najlepiej pasuje do obszarów obrazu zawierających pisany tekst.
Do eksperymentu, użyjemy implementacji K-Means z popularnego pakietu Scikit Learn. Parametrami naszej metody będzie liczba klastrów na które rozbijemy obraz, liczba losowych punktów z obrazu poddanych analizie oraz wartość startowa generatora liczb pseudolosowych. Pierwszym etapem będzie identyfikacja poszczególnych klastrów. W drugim etapie wydzielimy pojedynczy klaster i z niego skomponujemy nowy obraz.
Wyniki
Obrazy wyświetlone poniżej przedstawiają wynik rozbicia oryginalnego obrazu na 3 klastry. W celu wizualizacji punkty należące do danego klastra zostały zastąpione kolorem czerwonym. A zatem na pierwszym obrazie kolor czerwony odpowiada klastrowi nr 1, na drugim klastrowi nr 2, na trzecim – klastrowi nr 3.
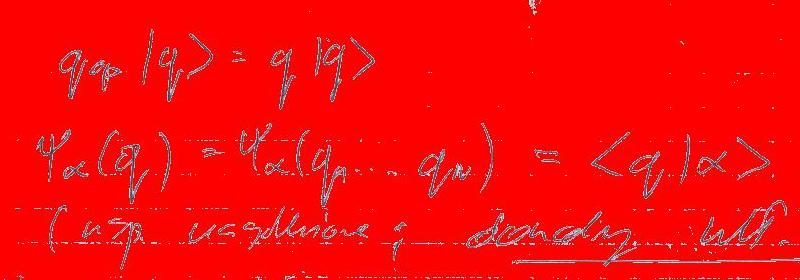
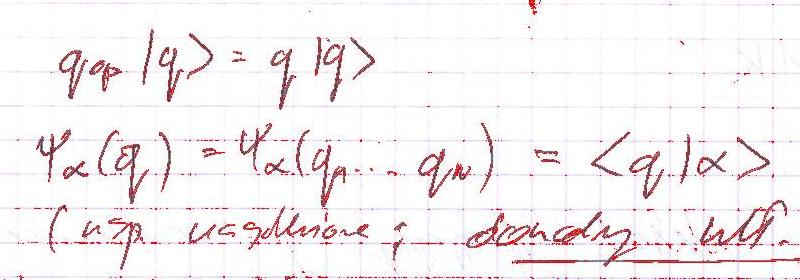
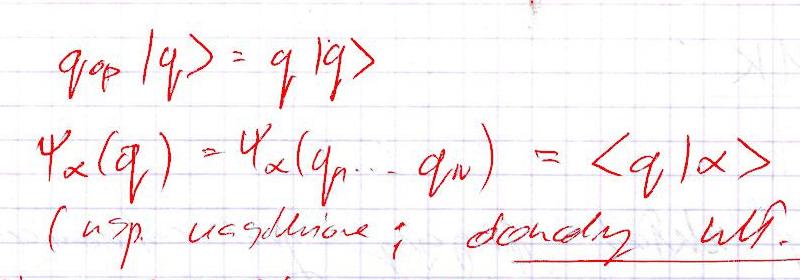
Pierwszy klaster objął biały kolor tła oraz jasne elementy (napisy przebijające z drugiej strony). Klaster number dwa to różne odcienie niebieskiego – “złapał” część niebieskiej kratki oraz interesującego nas tekstu. Najbardziej obiecująco wygląda trzeci klaster, który poza samym tekstem praktycznie nie obejmuje żadnych innych elementów obrazu. Zatem ostatecznie możemy nasz obraz poddać obróbce – usuwając z niego punkty należące do klastrów o numerach 1 i 2. Poniżej prezentujemy wynik tej operacji:

Podsumowanie
Osiągnięty wynik można uznać za zadowalający, zwłaszcza jeśli weźmiemy pod uwagę prostotę zastosowanego podejścia. Notatki po obróbce są czytelne (nie licząc charakteru mojego pisma). Znakomita większość niepożądanych elementów została usunięta. Niewątpliwie można by nieco popracować nad zachowaniem oryginalnego koloru tekstu oraz jego wygładzeniem. Dla chętnych do dalszych eksperymentów załączam kod źródłowy użyty przeze mnie podczas obróbki: decompose_image.py.
Mikołaj Sitarz, 2019
![]()
Ciekawe… a w przestrzeni HSV albo CMYK? Może coś więcej da się tam uzyskać?
HSV daje podobne wyniki, a CMYK nie próbowałem.